定义及符号
马尔可夫性质(Markov property):一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。以离散过程为例,随机变量
构成一个随机过程,这些随机变量的所有可能取值的集合被称为状态空间(state space),则 马尔可夫链(Markov chain):离散时间的马尔可夫过程。是最简单的的马尔可夫过程,其状态也是有限的。
范围(horizon):一个回合的长度,即每个回合最大的时间步。
策略:
- 确定性策略:
- 随机性策略:
- 确定性策略:
运动轨迹 (trajectory, episodes, rollouts):agent 和 environment 做一系列的交互后得到 state, action, reward 序列。
- agent 和 environment 交互 T 次:
是初始时智能体所处的状态,它只与环境有关。
- 当 agent 在某个
下采取 时,转移到某个状态 也分确定性和随机性; - 确定性:
- 随机性:
- 确定性:
- agent 和 environment 交互 T 次:
马尔可夫奖励过程
- 状态转移矩阵(state transition matrix):
, . - 马尔可夫奖励过程(Markov reward process, MRP):是马尔可夫链加上奖励函数。
- 奖励(reward)函数:
- 在某一次交互中,实际得到的奖励,可能是随机的;
- 奖励函数
表示在状态 下采取动作 转移到状态 后所获得的期望奖励;即 是奖励的期望值函数, 。 - 实际奖励
一般被视为条件概率分布下的随机变量; ,一般简写为 ,这是简化符号,省略了随机性,即会默认 R 是一个 deterministic 函数; - 奖励与策略无关。
- 回报(return):奖励的逐步叠加。
- 状态价值函数(state-value function):定义了状态的价值,是回报的期望。
- 贝尔曼方程(Bellman equation):
.
贝尔曼方程的推导,在上述状态价值函数的说明中已经体现,重点在于第 4 行到第 5 行的推导和变换。此处需要使用全期望公式。
马尔可夫决策过程
相对于马尔可夫奖励过程,马尔可夫决策过程多了决策(决策是指动作),其他的定义与马尔可夫奖励过程的是类似的。
- 状态转移矩阵变为:
. - 策略:根据状态决定采取怎样的动作。
.
假如已知马尔可夫决策过程和策略
下图为两者的对比备份图(backup): 每一个空心圆圈代表一个状态,每一个实心圆圈代表一个状态-动作对。
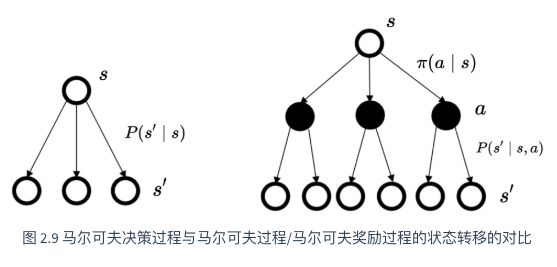
马尔科夫决策过程相比马尔可夫奖励过程,多了一层决策。值得注意的是:当智能体当前状态以及智能体当前采取的动作决定过后,智能体进入未来的状态其实也是一个概率分布。
马尔可夫决策过程的价值函数表达为:
动作价值函数(action-value function),即在某一个状态采取某一个动作,它有可能得到的回报的一个期望。
基于策略分布,对动作价值函数改写:
对动作价值函数进行贝尔曼方程推导:
根据式-1和式-2,或者根据备份图,可以得到贝尔曼期望方程:
核心概念
策略评估
已知:(1)马尔可夫决策过程;(2)采取的策略 。计算价值函数 的过程。 预测
预测是指给定一个马尔可夫决策过程()以及一个策略 ,计算它的价值函数,也就是计算每个状态的价值。 控制
控制(搜索最佳策略)的输入是马尔可夫决策过程;输出是最佳价值函数(optimal value function) 和最佳策略(optimal policy) 。
控制就是我们去寻找一个最佳的策略,然后同时输出它的最佳价值函数以及最佳策略。
示例说明
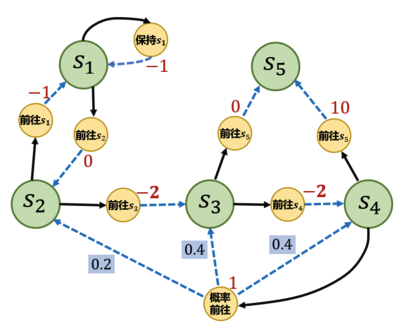
示例-1
绿色圆圈为状态,黄色圆圈为动作。
1 | S = ["s1", "s2", "s3", "s4", "s5"] # 状态集合 |
假设现在采用策略 Pi_1,将 MDP 转换成 MRP,如下:
1 | # 转化后的 MRP 的状态转移矩阵 |
蒙特卡洛方法(Monte-Carlo methods)
对于一个马尔可夫决策过程采用 MC 估计,已知策略为
步骤如下:
- 采用策略
采样若干条序列,第 i 条序列: ; - 对每条序列的每个时间步 t 的状态 s 进行操作:
代码实现:
1 | # 对所有采样序列计算所有状态的价值 |
最优策略
问题:如果只有马尔可夫决策过程,如何找到最佳策略,进而得到最优价值函数。
对于给定马尔可夫决策过程,至少存在一个策略比其他所有策略都好或者不差于。这个策略就是最优策略,最优策略可能有多个,都记为:
对应的最优状态价值函数为:
最佳策略使得每个状态的价值函数都取得最大值。所以如果我们可以得到一个最佳价值函数,就可以认为某个马尔可夫决策过程的环境可解。在这种情况下,最佳价值函数是一致的,环境中可达到的上限的值是一致的,但这里可能有多个最佳策略,多个最佳策略可以取得相同的最佳价值。
搜索最佳策略有两种常用的方法:策略迭代和价值迭代。寻找最佳策略的过程就是马尔可夫决策过程的控制过程。马尔可夫决策过程控制就是去寻找一个最佳策略使我们得到一个最大的价值函数值。
贝尔曼最优方程
贝尔曼最优方程表明:最佳策略下的一个状态的价值必须等于在这个状态下采取最好动作得到的回报的期望。当马尔可夫决策过程满足贝尔曼最优方程的时候,整个马尔可夫决策过程已经达到最佳的状态。
代入到贝尔曼方程中:
策略迭代
包含两步:
- 策略评估,即给定当前的策略函数来估计状态价值函数。
- 策略提升。
策略迭代算法如下:
价值迭代
策略迭代中,每一轮的策略提升都需要当前轮的策略评估完成,如此需要较大的计算量。可能出现这样的情况:虽然状态价值函数还没有收敛,但是不论接下来怎么更新状态价值,策略提升得到的都是同一个策略。
即基于:
价值迭代算法流程:
时序差分
基于动态规划的算法如:策略迭代和价值迭代,都需要马尔可夫决策过程已知。但是在大部分场景,马尔可夫决策过程的状态转移分布未知,agent 需要通过与环境的交互,采样数据来学习,属于无模型的强化学习。
无模型的强化学习不需要事先知道环境的奖励函数和状态转移函数。
同时,根据策略学习分为在线和离线:
- 在线策略学习:使用在当前策略下采样得到的样本进行学习,一旦策略被更新,当前的样本就被放弃了。
- 离线策略学习:使用经验回放池将之前采样得到的样本收集起来再次利用。因此,离线策略学习往往能够更好地利用历史数据,并具有更小的样本复杂度(算法达到收敛结果需要在环境中采样的样本数量),这使其被更广泛地应用。
时序差分是一种用来估计一个策略的价值函数的方法,结合了蒙特卡洛和动态规划算法。
蒙特卡洛方法对价值函数的增量更新方式:
在前面介绍的蒙特卡洛方法中,需要等整个序列结束之后才能计算这一次的
使用
附录
A. 随机变量是一个 mapping,函数也是一个 mapping,两者的区别是什么?
思考…
B.1 条件概率的加法规则:
B.2 联合条件概率分解
C. 全期望公式(law of iterated expectations, LIE)
如果
连续情况的积分表示:
将期望展开,则:
参考
- Easy RL:强化学习教程. 王琦, 杨毅远, 江季. 人民邮电出版社. link
- 动手学强化学习. 张伟楠, 沈键, 俞勇. link
- https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html